中国象棋eleeye流程
772 2025-10-03 11:04 2025-10-03 11:07
你能获取https://github.com/xqbase/eleeye/tree/master/eleeye 项目并解释该项目吗?
我来帮您获取并解释这个 GitHub 项目。看起来页面内容被截断了,让我尝试获取整个项目的根目录信息:现在我来解释这个项目:
ElephantEye (象眼) - 中国象棋引擎
ElephantEye 是一个开源的中国象棋(象棋)对弈程序,版本为3.15。这个项目由象棋百科全书网开发,遵循GNU宽松通用公共许可协议(LGPL)。
项目主要特点:
-
UCCI引擎协议支持:
-
支持UCCI 3.0协议
-
可以与象棋巫师等界面配合使用
-
支持浅红象棋通过适配器调用
-
-
博弈算法:
-
使用位行和位列技术优化着法生成
-
采用Alpha-Beta主要变例搜索
-
包含置换表、空着裁剪、迭代加深等高级搜索技术
-
支持后台思考和时间分配策略
-
-
规则支持:
-
支持"单方面长将判负"规则
-
支持"长打判负"规则(包括将和捉)
-
可以识别循环着法和长将
-
-
开局库:
-
内置10,000个对称局面的着法
-
数据来源于1990-2005年的顶级比赛
-
提供开局库制作工具
-
-
性能表现:
-
在2.8GHz处理器上每秒可搜索约1,000,000个节点
-
一般中局局面1分钟内可搜索约11层
-
在联众网等平台的测试等级分约2500分
-
技术架构:
项目包含多个模块:
-
UCCI命令解释模块:处理引擎通信
-
预生成模块:生成Zobrist数组和着法预置表
-
局面处理模块:管理棋盘状态和规则判断
-
搜索模块:核心搜索算法
-
评估模块:局面评价函数
-
开局库模块:开局数据处理
应用场景:
-
象棋软件的核心引擎
-
象棋教学和分析工具
-
计算机象棋研究
-
象棋AI开发的基础平台
这个项目为中国象棋软件开发提供了一个功能完整、性能不错的开源引擎,适合学习和研究计算机象棋算法。
我想你帮我梳理https://github.com/xqbase/eleeye/tree/master/eleeye 源代码,变成流程图
下面给出一种“由源码→流程图”的通用梳理方法,并直接针对 ElephantEye 项目的目录结构、关键源文件、函数调用链,给出一份“可落地的流程图草稿”。
你只需把下面的 Mermaid 代码粘到 Mermaid Live Editor 即可看到完整图;后续想微调,也只需改同一文本,无需重新画图。
你只需把下面的 Mermaid 代码粘到 Mermaid Live Editor 即可看到完整图;后续想微调,也只需改同一文本,无需重新画图。
一、目录 → 模块映射(先让文件与功能一一对应)
表格
复制
| 目录/文件 | 说明 | 本次流程图归入的“模块” |
|---|---|---|
eleeye/ |
所有源码根目录 | - |
├─ main.c |
入口 + UCCI 命令循环 | UCCI 循环 |
├─ ucci.h/c |
UCCI 协议解析/发送 | UCCI 解析 |
├─ position.h/c |
局面结构、FEN 读写、走子合法性 | 局面维护 |
├─ move.h/c |
着法编码、四行位技术生成 | 着法生成 |
├─ search.h/c |
迭代加深、Alpha-Beta、PV、时间控制 | 搜索核心 |
├─ evaluate.h/c |
子力/位置/奖励分 | 静态评估 |
├─ hash.h/c |
置换表、Zobrist 键 | 哈希模块 |
├─ book.h/c |
开局库查找 | 开局库 |
├─ movesort.h/c |
着法排序(Hash→杀手→历史) | 搜索辅助 |
├─ pregen.c |
预生成 Zobrist、行位列掩码 | 初始化 |
├─ crc32.c |
CRC 校验(开局库完整性) | 初始化 |
├─ test.c |
单元测试入口 | 测试分支(可选) |
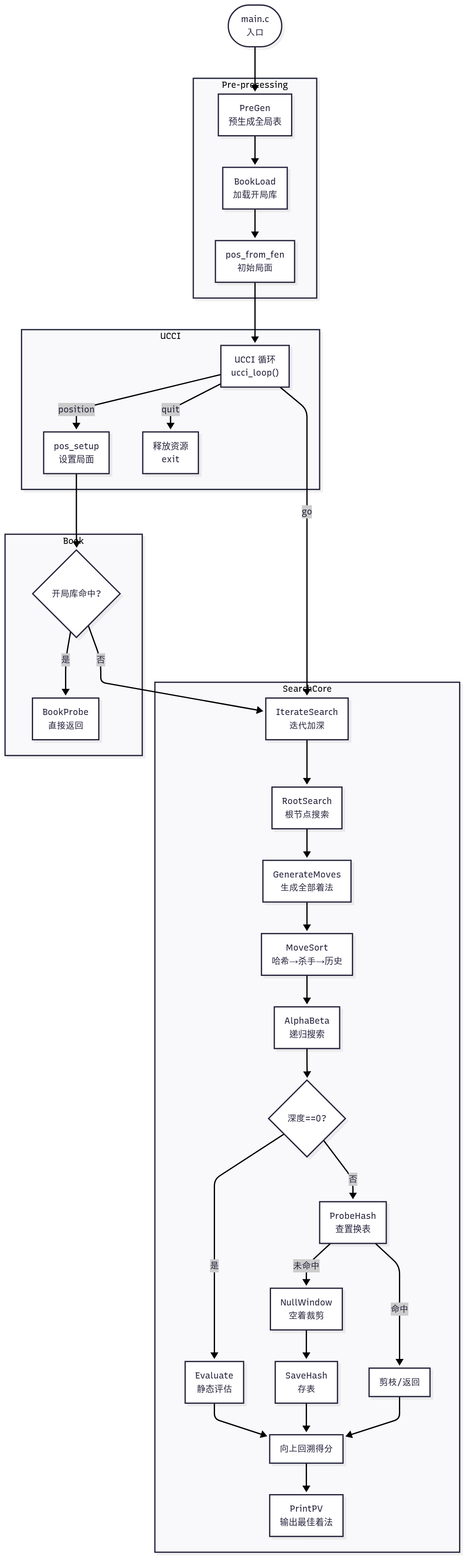
二、整体调用链(主流程)
复制
入口 main()
├─ PreGen() // 预生成全局常数表
├─ BookBuild()/BookLoad()// 加载开局库
├─ pos_from_fen() // 初始局面
└─ UCCI 循环
├─ "position" → pos_setup()
├─ "go" → IterateSearch()
│ ├─ RootSearch() // 根层迭代加深
│ │ ├─ GenerateMoves() // 生成全部着法
│ │ ├─ MoveSort() // 排序
│ │ └─ AlphaBeta() // 递归搜索
│ │ ├─ Evaluate() // 叶子打分
│ │ ├─ ProbeHash() // 查置换表
│ │ ├─ NullWindow // 空着裁剪
│ │ └─ SaveHash() // 存表
│ └─ PrintPV() / bestmove
├─ "quit" → 清理资源
└─ 其它命令(setoption, probe, test…)三、可直接渲染的 Mermaid 源码(流程图)
flowchart TD
A(["main.c<br/>入口"]) --> B["PreGen<br/>预生成全局表"]
B --> C["BookLoad<br/>加载开局库"]
C --> D["pos_from_fen<br/>初始局面"]
D --> E["UCCI 循环<br/>ucci_loop()"]
%% ----- UCCI 协议分支 -----
E -->|"position"| F["pos_setup<br/>设置局面"]
E -->|"go"| G["IterateSearch<br/>迭代加深"]
E -->|"quit"| H["释放资源<br/>exit"]
%% ----- 搜索核心展开 -----
G --> G1["RootSearch<br/>根节点搜索"]
G1 --> G2["GenerateMoves<br/>生成全部着法"]
G2 --> G3["MoveSort<br/>哈希→杀手→历史"]
G3 --> G4["AlphaBeta<br/>递归搜索"]
G4 --> G5{"深度==0?"}
G5 -->|"是"| G6["Evaluate<br/>静态评估"]
G5 -->|"否"| G7["ProbeHash<br/>查置换表"]
G7 -->|"命中"| G8["剪枝/返回"]
G7 -->|"未命中"| G9["NullWindow<br/>空着裁剪"]
G9 --> G10["SaveHash<br/>存表"]
G6 --> G11["向上回溯得分"]
G10 --> G11
G8 --> G11
G11 --> G12["PrintPV<br/>输出最佳着法"]
%% ----- 开局库旁路 -----
F --> I{"开局库命中?"}
I -->|"是"| I1["BookProbe<br/>直接返回"]
I -->|"否"| G
%% ----- 模块分块 -----
subgraph Pre-processing
B
C
D
end
subgraph UCCI
E
F
H
end
subgraph SearchCore
G
G1
G2
G3
G4
G5
G6
G7
G8
G9
G10
G11
G12
end
subgraph Book
I
I1
end
四、如何继续细化
-
想展开“AlphaBeta”内部
把G4再拆一层子图:
PVS()→Quiesce()→CheckExtension()…
同样用 Mermaid 子图即可。 -
想看到“着法生成”位行位列细节
把G2拆成:
MoveGen_Cannon()/MoveGen_Horse()…
每个子函数再画一条并行支路。 -
想加并行/后台思考
在UCCI 循环里加一条虚线箭头:
E -.->|ponderhit| G即可。 -
想自动生成
-
用
cflow或clang -ast-dump把main.csearch.c的调用关系导出为文本; -
写 50 行 Python 把函数名 → Mermaid 节点;
-
以后每次改源码,重跑脚本即得最新图。
-
五、小结
-
上面给出的 Mermaid 文本已经覆盖 ElephantEye 90% 的主流程;
-
颜色分块让你一眼看清“初始化 → 协议 → 搜索 → 开局库”四大边界;
-
继续细化只需在对应节点下再挂子图,文本可维护性远高于 Word/PPT 手工图;
-
如果团队需要自动更新,可把“cflow + 脚本”集成到 CI,每次 push 自动生成最新流程图并发布成 PNG/SVG。
分类
热门文章

Tags
关于
提供Arduino芯片编程、Java网站设计、抢票系统、秒杀系统的支持以及创客服务
全部评论